시간은 점점 늦어가는데 잠은 안 온다. 조카랑 너무 신나게 논 탓일까? 아이가 부모한테서 떨어지기 싫은 것 만큼이나, 부모도 아이한테서 떨어지기 힘들다는 말이 실감나는 밤이다. 흐음... 글이나 쓰자~
요새 영어 공부를 하고 있는데, 영어 공부는 안 하고, 영어 사전만 찾고 있다. 헐~~ 먼저 소개할 사전은 StarDict 사전이다. 좋은 사전의 첫 번째 요건은 풍부한 어휘이다. 그리고, 사용하기 편리한 것. 마지막으로 자신의 스타일에 어울리는 사전일 것이다. StarDict 는 우선 사전 데이터가 풍부하다. 얼마나 풍부하냐 하면...
여기에 더해서, 한글 관련 사전도 이렇게나 있다.
이 모든 사전들이 free 이거나 GPL 이다. 이제 어떻게 사전을 설치하는지 알아보자. 먼저, StarDict 다운로드로 가서 윈도우 용을 다운 받아서 설치한다. 그럼, 기본적으로 wordnet-3.0.0 사전이 설치되어 있다.
사전을 추가하려면, StarDict 사전으로 이동해서 원하는 사전의 tarball 을 클릭해서 다운 받는다. winrar 로 *.tar.bz2 파일의 압축을 풀어준다.
압축을 푼 후에 C:\Program Files\StarDict\dic\ 아래로 폴더째 복사해서 넣으면 된다. 예를 들어, stardict-quick_eng-kor-2.4.2 를 넣었다면, C:\Program Files\StarDict\dic\stardict-quick_eng-kor-2.4.2\ 가 될 것이다. 그리고 나서 StartDict 를 재실행하면 사전이 등록된다. 사전이 제대로 등록되었는지 보려면, 우측 하단의 Y 자 모양 아이콘을 클릭하면 된다.
그럼, 아래와 같이 quick_eng-korean 이 등록된 것을 볼 수 있다.
사전 데이터는 위의 링크 말고도 http://www.stardict.org 나 http://app.weiphone.com/wedict/upload/files 에서 다운 받을 수 있다. Sisa_e4u 사전은 구글링하면 다운받을 수 있는데, 발음기호나 한문이 깨져서 보일 수 있다. 여기에서 말하는 것처럼 사전을 decompile 한 후, hex editor 로 일부를 수정한 후, 다시 compile 하면 된다. (이 작업을 하지 않으면 검색에 포함되지 않는 영어 단어도 생긴다) 그리고, 한문이 깨져서 보이는 것은 폰트 설정의 문제이므로, 유니코드를 지원하는 폰트를 지정해 주면 된다. 우측 하단의 스패너 모양의 아이콘을 클릭하면 폰트를 변경할 수 있다.
MS Office 를 설치했을 때 생기는 Arial Unicode MS나, 아래아 한글을 설치했을 때 생기는 Haansoft Batang 이나 Haansoft Dotum 정도로 설정하면 적당하다.
이렇게 해서 StarDict 사전을 설치하는 것을 해 보았다. 수 많은 사전 데이터를 돈을 내지 않고 사용할 수 있는 장점이 있다. 하지만, 디렉토리에 넣어주어야 하고, 쓸만한 한영사전이 Sisa_e4u 밖에 없는데, 발음 기호 표현이 약간 문제가 있는 한계가 있다. 다음 글에서는 입이 더 벌어질만한 사전을 소개한다.
요새 동영상이 대세인 것 같다. 예전의 PMP 를 비롯해, PSP, 요새 iPod touch, 그리고 전자 사전에서 제공하는 동영상 기능, 그리고 좋은 핸드폰들... 하지만, 이렇게 편리한 기기들이 있어도 동영상을 보지 못하는 한 가지 장벽이 있으니, 바로 "인코딩" 이라는 벽이다. 한편, "인코딩" 을 해주는 프로그램인 "인코더" 도 봇물처럼 나오고 있다. 우선 다음 팟 인코더 가 있고, 곰 인코더도 있다. 조금 더 찾아보면, 바닥이나 여러 가지 무료로 쓸 수 있는 인코더 들이 있다. 그 중, 다음 팟 인코더나 곰 인코더가 사용하기 편리한 인터페이스를 갖추고 있는 것 같다.
난 주로 다음 팟 인코더를 사용하는데, 곰 인코더가 좋다는 말을 들어 보았다. 그러나, 사용하려니 곰 인코더는 로그인을 해야 하고, 사용하려면 월 1000원을 내야 한다. 음... 프로그램에 적당한 사용료를 줄 필요는 있는데, 다른 쪽에서 무료로 제공하고 있으니 참 난감하다---;
아무튼 친구의 전자사전 iRiver 딕플 D5에 동영상을 넣어주려고 하는데, 어떻게 넣어야 하는지 모르겠다. 대충 400 x 240 해상도, 15 프레임을 재생할 수 있다고 하는데, 인코딩 설정할 게 너무 많다. 다행히 곰 인코더에서는 현재까지 나온 수많은 기기에 적합한 인코딩 설정을 제공해 준다. 그래서, 곰 인코더에서 설정을 확인하고, 다음 팟 인코더에서 인코딩 솩솩~~
예전에는 Yahoo! 미니 사전을 사용했었다. 이 사전은 Hooking 기능을 사용해서 마우스를 갖다 대면 밑줄이 쫙 그어지고, 사전 검색 결과를 보여주는게 재미있었다. 그러나, 가끔씩 나의 의지와 상관없이 튀어나오는 업데이트 메세지가 탐탁치 않았다. 요새는 주로 Naver 영어 사전이나 Daum 영어 사전을 사용한다. 숙어나 문장까지 검색되는 것으로는 가장 좋은 사전이 아닐까 생각한다. 특히 네이버는 작은 창을 띄워 놓고 작업할 수 있어 편리하다.
그러나, 이 사전들은 인터넷에 연결되어 있어야 사용할 수 있다는 점~~! 매번 인터넷이 되는 장소로 찾아가기도 번거롭고, 무엇보다도 인터넷이 연결되어 있으면 번역하다가 샛길로 새기가 쉽다. ㅎㅎ 아는 분의 부탁으로 iPod Touch 에 영어 사전을 설치해 주게 되었다. 너무 너무 너무 사전이 풍부하고 좋아서, 나도 iPod Touch 를 지르고 싶은 마음이 차올랐다. 하지만, 주머니 사정을 고려해서 일단 접고... iPod Touch 에 설치했던 WeDict 를 내 PMP(T43 DIC) 에 설치해보려고 노력했다.
우선 WeDict 는 오픈 소스 형태인 StarDict 프로젝트로 공개되어 있었다. 그리고, 큐토피아용으로 만들어진 소스도 있었다. But... 소스만 있어서, 컴파일 해야 한다. mipsel 로 누가 컴파일 해주면 좋으련만... 이걸 컴파일 하려고 리눅스를 다시 깔기엔 너무 번거롭다. 헐~~~ 난, 그 대신 Zbedic 을 PMP 에 설치했다. 사전 데이터는 나중에 다운 받아 넣어봐야 겠다. (설치방법, 문제해결1, 문제해결2, 사전데이터1, 사전데이터2 ,Tree explorer 는 문제해결2에서 다운)
일단 StarDict 를 PMP 에 설치하는 것은 유보~ 그렇다고, 물러날 내가 아니다. 오픈소스이므로 windows 용도 있을 것이라는 추측에 검색해 보니, 여러 가지 결과가 나왔다. Windows 버젼을 다운 받아 설치하고, 사전 데이터(1, 2, 3)를 추가하면 된다. 사전 데이터는 *.dz 압축을 풀어도 되고 안풀어도 된다.
사전 중에 가장 필요한 사전이 풍부한 영한 사전일 것이다. Google 로 잘 검색해 보면 Sisa_e4u 데이터가 있다. 하지만, 이 사전의 단점 하나~ 발음기호가 깨진 경우 검색 결과 자체에 포함 되지 않는다. (예: love) 여기를 참고해서 사전 데이터를 수정해 주면 된다. notepad++ 에 hex edit 플러그인으로 했다가 시간이 너무 오래 걸려서, winhex 로 했더니 몇 초밖에 걸리지 않았다. (그래도 accent 가 붙은 발음 기호는 ? 로 나타나지만, 검색에는 지장이 없다.) (참고1, 참고2, 참고3)
추가로 iPod touch 에 설치하는 방법, 레퍼드 사전에 추가하는 방법(1, 2)도 있다. iPod 1 세대는 해킹한 후에 WeDict 데이터 디렉토리에 *.idx 와 압축이 풀린 *.dict 파일을 넣어주면 된다. 2세대는 해킹이 되지 않았으므로, WeDict Pro 의 "Upload dictionaries" 메뉴를 사용한다. 그러면 1234 포트를 열어주는데, ftp 전송 프로그램으로 *.idx 와 *.dict 를 전송해 주면 된다.(1, 2, 3)
스트레스 관련 글은 쓰지 않고, 연달아 컴퓨터 관련 글이다. 게다가 불친절한 only 텍스트 모드의 글! 후훗~ 프로그래머 본성인가?
한번에 DVD 에서 자막을 만들어내지 못하는 이유는 DVD 에 텍스트 형태의 자막이 들어있지 않기 때문이다. 아래를 보면 DVD 에 자막이 어떻게 들어있는지 볼 수 있다. DVD 자막은 그림파일 형태로 들어있다. 그림 파일이 아니라면, DVD 플레이어들은 폰트를 내장해야 할 것이다. 그래서 VobSub 에서 자막을 추출할 때에는 이미지 인식 방법을 사용한다. 아래와 같이 'a' 처럼 보이는 문자는 a 로 인식하기로 입력하면, 앞으로 나오는 모든 이미지들은 a 로 인식할 수 있다. 이렇게 입력된 문자들을 바탕으로 동일한 이미지 패턴에 대해서는 동일한 문자로 취급하고 넘어간다. 그래서, 어느 정도 입력하다 보면 거의 대부분 인식이 된다. 처음 하는 사람은 3~4시간 정도, 익숙해지면 1시간 정도면 할 수 있다고 한다. 그리고 영어보다, 한글이 오래 걸린다고 한다.
그래서 나도 그냥 해 보았다. 그러나, 하다가 실수로 'a' 를 다른 문자로 넣은 경우에 되돌릴 수가 없었다.(이는 기록해 두었다가 나중에 한꺼번에 바꾸기를 하면 된다고 한다.) 그리고, 중간에 하다가 멈추면 처음부터 다시 시작해야 했다. 나두 자리에 앉아서 같은 일을 여러 번 반복하는 것에 쉽게 질리지 않는 편인데, 이 작업은 정말 지루했다. 그리고, 계속 실수를 해서 짜증이 났다. 한편, 그동안 수많은 자막 작업을 해 주신 분들에게 감사의 마음도 올라왔다. 결국 성질나서 그만 뒀다--;
요새 Acrobat 보면 문자 인식률이 좋던데, 혹시 문자 인식 프로그램은 없을까? 그래서 Microsoft Office 2003 의 "Microsoft Office Document Imaging" 을 사용하는 SubtitleCreator v.2.2 를 사용해서 변환해 보았다. 그리고, 문자 인식률을 높이기 위해 자막 파일을 조금 수정해서 자막 인식을 진행해 보았다.
[환경 설정 - Microsoft Office 2003 Document Imaging 설치] 우선 Microsoft Office Document Imaging 이 설치되어 있지 않다면, 설치 변경을 해서 내 컴퓨터에서 실행이 되도록 설치를 변경한다.(Office 2007 의 Microsoft Office Document Imaging 으로는 내 노트북에서 제대로 동작하지 않았다.)
[작업1 - DVD에서 자막 추출] 자, 그럼 인제 자막을 추출해 보도록 한다. 먼저 DVD 에서 자막을 추출한다. [강좌] DVD에서 영상과 음성파일을 추출해보자 를 참고하여, PgcDemux를 실행한다. 이번에는 "subpic streams" 을 선택한다. 원하는 Movie 의 *.IFO 파일을 택하고, Mode 에서 "by VOB id" 를 택하고, Domain 에서 "Titles" 택한 다음, 말림 막대에서 Movie 를 선택해서 추출하고자 하는 동영상을 찾는다. "Process!" 를 클릭하면, 음성이나 동영상을 추출할 때와 비슷한 시간이 걸린다. (고로, 한번에 세 가지를 다 추출해 놓으면 편하다.) 이번에는 Subpictures_20.sup 와 Subpictures_21.sup 파일 두개가 만들어진다. (20은 한국어 자막파일이고, 21은 영어자막파일이다.)
[작업2 - 자막 파일 변경] 두 번째로는 *.sup 파일을 조금 수정한다. 자막이 한 문장으로 짧게 되어 있는 경우에는 Office Document Imaging 이 제대로 인식하지 못하기 때문이다. 아래 파일을 다운 받아 *.sup 를 생성한 폴더에 저장한다. (코딩 안하려고 발버둥 쳤건만, 결국 만들게 되었다.)
파일이 변경되었는지 체크하기 위해 md5 해쉬 파일도 같이 첨부한다. md5 파일은 어떻게 만드는 건가요? 답변에 나온대로 HashCheckInstall-latest.exe 을 설치한 후, 아래 md5 파일을 sup2sub.exe 가 있는 폴더에 저장한다. 그리고, md5 파일을 더블클릭하면 파일이 변조되었는지 여부를 알 수 있다.
도스 실행파일이어서 command 창으로 작업을 해야 한다. "윈도우 키 + r" 을 눌러 "실행" 창을 열고, cmd 라고 입력하고 확인을 누른다.
그리고 나서 cd 명령을 사용해서, *.sup 와 sup2sub.exe 가 있는 디렉토리로 이동한다. (위의 윈도우 탐색기의 주소를 복사한 후, 도스 창에서 마우스 우클릭 하고 붙여 넣기를 하면 된다.)
그리고, sup2sub.exe -create Subpictures_20 라고 치고 엔터를 누르면 변환이 된다.(Subpictures_20.sup 라고 치지 않는다) 마찬가지로 Subpictures_21 에 대해서도 변환을 해준다. 그러면, Subpictures_20.idx, Subpictures_20.sub, Subpictures_21.idx, Subpictures_21.sub 파일 두 쌍이 생성된다.
[작업3 - SubtitleCreator 로 자막 인식] 세 번째로, SubtitleCreator v.2.2 를 다운 받아서 설치한다. (user guide 를 보면 .NET framework 2.0 가 필요하다. 설치하지 않으면 아마 실행 오류가 날 것이다. Vista 는 이미 .NET framework 3.0 이 설치되어 있으므로 괜찮다. 그리고 내 노트북에서 SutitleCreator v.2.31 로는 자막 인식이 제대로 동작하지 않았다.) 실행 뒤에 나오는 야시시한 그림이 불편하다면, C:\Program Files\SubtitleCreator\Data 폴더에 있는 NTSC720x480.jpg 와 Pal720x576.jpg 파일을 교체하면 된다. 파일 이름은 같고, 빈 그림 파일들로 만들어서 첨부한다.
이제 Subtitle Creator 를 실행하고, 메뉴에서 "Tools" > "Recognize text using OCR" 를 실행한다. 한국어를 먼저 할 것이기 때문에 Language 옵션에서 KOREAN 을 선택해 주었다. 그리고, 아래에 있는 "Open file for Optical Character Recognition" 을 클릭한다.
*.SUP 파일은 exception 이 발생하므로, VobSub 파일을 선택하도록 한다. 그리고, 약 4~5 분 정도 기다리면 텍스트를 자동으로 인식한다. (두근두근~ 얼마나 잘 인식되었을까 궁금한 순간이다.) 결과물로 Subpictures_20.srt 자막 파일이 생성된다.
[작업4 - srt 자막 파일을 smi 자막 파일로 변경] 이렇게 해서 자막 만들기가 마무리 되었다. SRT→SMI 변환 툴을 사용해 *.srt 파일을 *.smi 파일로 바꾸면 된다. 먼저 영어 자막인지, 한글 자막인지 구별해서 언어를 선택한다. 그리고, "Open and convert and save" 메뉴를 클릭해서 위에서 생성한 *.srt 파일을 선택하면 자동으로 변환이 된다.
[수정 작업 - 자막 이미지와 자막의 비교] 그런데, 자막이 100% 완전하게 인식되지는 않는다. 추가적으로 손을 보아야 하는데, "Tools" > "Translate SUP or VobSub to SRT" 를 실행해서 손을 볼 수 가 있다. 아래 창이 뜨는데, 첫번째로 나오는 IFO 파일은 지정하지 않아도 된다. 두 번째에 있는, IDX or SUB 파일은 위에서 만든 파일로 지정한다. 세 번째에 나오는, SRT 파일은 이미 자동으로 생성되어서 지정되어 있을 것이다.
아래와 같이 자막의 그림 파일과 인식된 *.srt 파일을 비교하면서 일일이 손을 볼 수가 있다. 원하는 만큼 작업한 후 저장해 놓으면, 나중에 다시 작업할 수 있다. 버그가 하나 있는데, *.srt 의 문장 갯수가 맞지 않는다는 에러 메세지가 나올 때가 있다. 이것은 *.srt 파일의 마지막 자막이 기록이 안 된 경우이다. *.srt 파일을 (메모장으로) 열어 (아무렇게나) 자막의 개수를 맞춰주면 편집이 가능하다. 혹은 자막 이미지 자체를 SubtitleCreator 가 제대로 보여주지 못하는 경우도 있는데, 이 때는 VobSub 을 설치해서 SubResync 로 자막 파일을 열어보면 제대로 보인다.
| 기호 : 줄 바꿈
[] 기호나 () 기호 : 내용을 사라지게 한다.(사용하지 않는 것이 좋음)
Ctrl + S : 현재까지 작업한 내용 저장 ( 이미, 5분 간격으로 자동 저장 기능이 동작하고 있음)
이렇게, 이렇게 해서 자막 만들기가 마무리 되었다. 어째 VobSub 으로 하는 것보다 훨씬 더 복잡해 보인다. ㅎㅎ 그리고, 아직은 문제도 좀 있다. 하지만, 한글이 인식된다는 장점이 있다.
그리고 나중에 다국어가 인식이 될 가능성이 있다. Non-English OCR in Microsoft Office Document Imaging (MODI) 글을 보면, OS 에서 해당 언어팩을 설치한 후, Office language pack(about $25/lang pack)을 설치하고, 언어마다의 service pack 을 설치하면 해당 언어가 인식 된다고 한다. 하지만, 내가 테스트해 본 바로는 Office2007 Document Imaging 환경에서는 SubtitleCreator 의 OCR 인식이 동작하지 않았다. 그리고 다국어 언어를 테스트 해보기 위해서는 Windows MUI(Multilingual User Interface)로 OS 를 깔아서 테스트해 보아야 한다.
둘째로, 나한테 자막파일을 처리할 수 있는 기술이 생겼다. 자막 specification 도 있고, 자막을 처리하는 간단한 소스도 있다. 조금씩 손 보면 [작업2번] 부터 자동화가 가능하다. 자~ 자~ 이제 부터는 다시 stress 관련 글을 쓰련다. 다시 일상으로 go back ~~
다음으로 동영상을 만들기를 해본다. 오히려 동영상 쪽이 편리한 툴이 있어서, 음성 추출하기 보다 수월하다. 역시 [강좌] DVD에서 영상과 음성파일을 추출해보자를 참고해서 만들어 보았다. 이번에는 PgcDemux 를 실행한 후, Option 에서 "audio streams" 에 더해 "video streams" 을 체크한다. 원하는 Movie 의 *.IFO 파일을 택하고, Mode 에서 "by VOB id" 를 택하고, Domain 에서 "Titles" 택한 다음, 말림 막대에서 Movie 를 선택한다. 대충 재생 시간을 보면 제대로 택했는지 알 수 있다. 음성과 영상을 같이 추출해도 음성을 추출할 때와 시간이 비슷하게 걸린다. 45분 Movie 에서 영상과 음성 같이 추출하는데 걸린 시간은 7분 정도이고, 생성된 파일은 VideoFile.m2v 와 AudioFile_80.ac3 두 개이다
다음으로 tsMuxeR 을 실행해서 Iput files 에 위에서 생성한 파일들을 추가한다. 추가하는 방법은 "add" 를 클릭해서, 위에서 생성한 두 개의 파일을 하나씩 넣어주면 된다. 추가할 때는 몇 초 정도씩 걸린다. 그리고, 다음으로 할 일은 제일 아래에 있는 버튼 "Start muxing" 을 누르는 것이다. 이렇게 간단할 수가~! 결과물로 *.ts 파일이 생성된다. 걸리는 시간은 45분 짜리 동영상에 7분 정도였다. 아직까지는 시간이 그리 오래 걸리지 않는 작업들이다.
마지막으로 동영상을 인코딩만 하면 된다. 인코딩은 동영상의 크기를 줄이는 작업이다. 동영상 화면 사이즈를 조절하기도 하고, 적당한 압축 알고리즘으로 화면을 압축하기도 한다. 위에서 만든 *.ts 파일은 압축되지 않은 원본 파일인데, 크기가 2G 정도 된다. CD 로 굽거나, PMP 에 넣기에는 용량이 좀 크다. Daum 팟 인코더를 써봤는데, 세상 참 좋아졌다는 생각이 든다. 너무 편리하게 한 방에 인코딩이 된다. [강좌] 인도영화의 중의 M/V를 만들어보자-1부를 참고해서 작업해 보았다.
위에서 만든 *.ts 를 불러오고, 세부 설정을 한 다음에 "인코딩 시작" 버튼을 누르면 된다. 내 노트북에서는 2x 정도의 속도로 인코딩이 되었다. 즉, 45분 짜리 동영상을 바꾸는데, 약 20분이 더 걸렸다. 2G 정도 되는 동영상이 200M 정도로 줄어들었다.
또한 Daum 팟 인코더는 원하는 시간만큼 추출해서 편집할 수 있다. 일부만 잘라서 인코딩한 후 자신의 휴대용 기기에 넣어 재상이 되는지 확인해 보면 시간을 절약할 수 있다. 재생이 안된다 싶으면, 세부 설정에서 자신의 휴대용 기기가 지원하는 압축 방식으로 지정하면 된다.
이렇게 해서 동영상 인코딩도 끝~ 다음 팟 인코더는 *.flv 파일도 인코딩 할 수 있다. 즉, YouTube 나 다른 동영상 사이트에서 플래시 동영상 파일을 다운 받아서 원하는 형태로 바꿀 수 있는 것이다. 또한 요즘 인기 끌고 있는 iPodTouch 에 넣을 수 있게 바꿀 수도 있다. 그럼, 다음 글에서는 드디어 탄생의 기쁨을 맛보게 한 '자막 만들기' 를 포스팅 해 본다~















 sup2sub.exe
sup2sub.exe sup2sub.exe.md5
sup2sub.exe.md5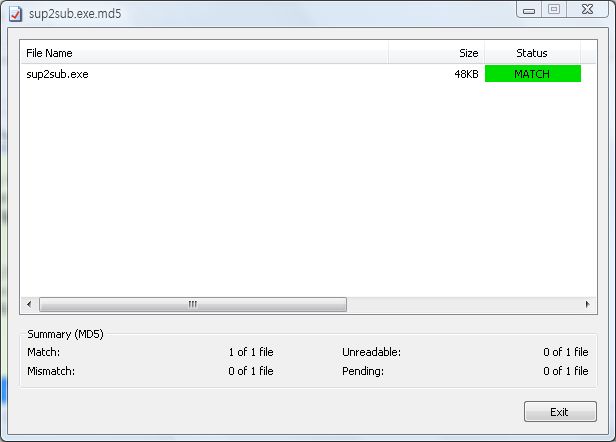




 SubtitleCreator2.2_Data.zip
SubtitleCreator2.2_Data.zip